hdfs全称为hadoop分布式文件系统,是hadoop核心组件之一,作为大数据生态底层的分枝存储服务而存在。也可以说大数据首先要处理的问题就是海量数据的存储问题,下面将从功能介绍、部署、以及基本使用几个部分来介绍HDF文件系统
简介
hdfs主要是用于处理大数据存储问题的,分布式意味着hdfs是横跨在多台计算机上的存储系统
hdfs是一种能够在普通硬件上运行的分布式文件系统,他是高容错的,适应于具有大数据收集的应用,非常适合存储TB以及PB级别的大型数据
hdfs使用多台计算机存储文件,并且提供统一的访问入口,操作体验像是访问普通文件系统一样使用分布式文件系统
设计目标
hdfs对文件采用write-one-read-many访问模型,一个文件一旦创建、写入、关闭之后就不能修改了,这一模型简化了数据一致性问题,使高吞吐亮的数据访问成为可能
移动计算的代价相较于移动数据的代价更低,一个应用请求的计算,离它操作的数据越近就越高效,将计算移动到数据附近,比将数据移动到应用所在显然更好
hdfs被设计为可从一个平台轻松移植到另一个平台。有助于将hdfs大量应用程序的首选平台
特性
采用主从结构、分块存储
副本记录机制、卷数据集记录
抽象统一的目录结构
主从架构
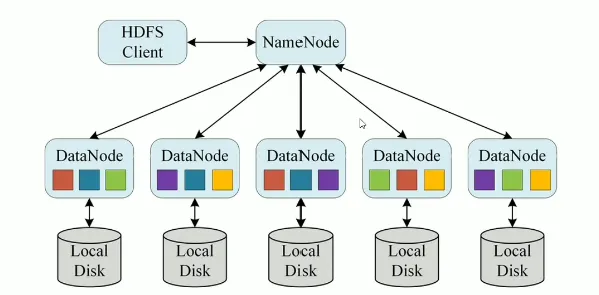
hdfs集群是标准的master/slave主从架构集群
一般一个HDFS集群是有一个namenode和一定数目的Datanode组成
namenode是hdfs主节点上,datanode是hdfs从节点,两种角色各司其职,协同完成分布式的文件存储服务
官方架构图是一主五从模式,其中五个从角色位于两个机架的不同服务器上
hadoop shell常用操作
创建数据目录
#创建数据目录
hadoop fs -mkdir [-p] <path> ...
[root@node1 ~]# hadoop fs -mkdir -p /day001/test
[root@node1 ~]# hadoop fs -ls /
Found 4 items
drwxr-xr-x - root supergroup 0 2025-04-29 19:25 /day001
drwxr-xr-x - root supergroup 0 2025-04-29 02:23 /test
drwx------ - root supergroup 0 2025-04-29 02:31 /tmp
drwxr-xr-x - root supergroup 0 2025-04-29 02:30 /user文件查看
#查看本地文件系统根目录下
hadoop fs -ls file:///
#查看某个节点下hdfs文件系统
hadoop fs -ls hdfs://node1:8020/
Found 3 items
drwxr-xr-x - root supergroup 0 2025-04-29 02:23 hdfs://node1:8020/test
drwx------ - root supergroup 0 2025-04-29 02:31 hdfs://node1:8020/tmp
drwxr-xr-x - root supergroup 0 2025-04-29 02:30 hdfs://node1:8020/user
#查看指定目录下内容
hadoop fs -ls [-h] [-R] [<path> ...]
-h 人类可读 -R 递归查看指定目录及其子目录
[root@node1 ~]# hadoop fs -ls /
Found 5 items
-rw-r--r-- 3 root supergroup 2807 2025-04-29 19:31 /anaconda-ks.cfg
drwxr-xr-x - root supergroup 0 2025-04-29 19:25 /day001
drwxr-xr-x - root supergroup 0 2025-04-29 02:23 /test
drwx------ - root supergroup 0 2025-04-29 02:31 /tmp
drwxr-xr-x - root supergroup 0 2025-04-29 02:30 /user
[root@node1 ~]# hadoop fs -ls -h /
Found 5 items
-rw-r--r-- 3 root supergroup 2.7 K 2025-04-29 19:31 /anaconda-ks.cfg
drwxr-xr-x - root supergroup 0 2025-04-29 19:25 /day001
drwxr-xr-x - root supergroup 0 2025-04-29 02:23 /test
drwx------ - root supergroup 0 2025-04-29 02:31 /tmp
drwxr-xr-x - root supergroup 0 2025-04-29 02:30 /user
[root@node1 ~]# hadoop fs -ls -h -R /
-rw-r--r-- 3 root supergroup 2.7 K 2025-04-29 19:31 /anaconda-ks.cfg
drwxr-xr-x - root supergroup 0 2025-04-29 19:25 /day001
drwxr-xr-x - root supergroup 0 2025-04-29 19:25 /day001/test
drwxr-xr-x - root supergroup 0 2025-04-29 02:23 /test
-rw-r--r-- 3 root supergroup 2.7 K 2025-04-29 02:23 /test/anaconda-ks.cfg
drwx------ - root supergroup 0 2025-04-29 02:31 /tmp
drwx------ - root supergroup 0 2025-04-29 02:30 /tmp/hadoop-yarn
drwx------ - root supergroup 0 2025-04-29 02:31 /tmp/hadoop-yarn/staging
drwxr-xr-x - root supergroup 0 2025-04-29 02:31 /tmp/hadoop-yarn/staging/history
drwxrwxrwt - root supergroup 0 2025-04-29 02:31 /tmp/hadoop-yarn/staging/history/done_intermediate
drwxrwx--- - root supergroup 0 2025-04-29 02:31 /tmp/hadoop-yarn/staging/history/done_intermediate/root
-rwxrwx--- 3 root supergroup 25.8 K 2025-04-29 02:31 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1745915885556_0001-1745919059649-root-QuasiMonteCarlo-1745919098955-2-1-SUCCEEDED-default-1745919072171.jhist
-rwxrwx--- 3 root supergroup 445 2025-04-29 02:31 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1745915885556_0001.summary
-rwxrwx--- 3 root supergroup 255.8 K 2025-04-29 02:31 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1745915885556_0001_conf.xml
drwx------ - root supergroup 0 2025-04-29 02:30 /tmp/hadoop-yarn/staging/root
drwx------ - root supergroup 0 2025-04-29 02:31 /tmp/hadoop-yarn/staging/root/.staging
drwxrwxrwt - root root 0 2025-04-29 02:31 /tmp/logs
drwxrwx--- - root root 0 2025-04-29 02:31 /tmp/logs/root
drwxrwx--- - root root 0 2025-04-29 02:31 /tmp/logs/root/bucket-logs-tfile
drwxrwx--- - root root 0 2025-04-29 02:31 /tmp/logs/root/bucket-logs-tfile/0001
drwxrwx--- - root root 0 2025-04-29 02:31 /tmp/logs/root/bucket-logs-tfile/0001/application_1745915885556_0001
-rw-r----- 3 root root 105.3 K 2025-04-29 02:31 /tmp/logs/root/bucket-logs-tfile/0001/application_1745915885556_0001/node1.itcast.cn_40988
-rw-r----- 3 root root 73.9 K 2025-04-29 02:31 /tmp/logs/root/bucket-logs-tfile/0001/application_1745915885556_0001/node2.itcast.cn_42418
drwxr-xr-x - root supergroup 0 2025-04-29 02:30 /user
drwxr-xr-x - root supergroup 0 2025-04-29 02:31 /user/root文件上传
#上传至文件系统
hadoop fs -put [-r] [-p] <本地文件> <目的地>
hadoop fs -put anaconda-ks.cfg /文件查看
hadoop fs -cat <文件名>
hadoop fs -tail <文件名>下载与拷贝
hadoop fs -get [-f] [-p] <目标文件> ... <本地位置>
-f 覆盖目标文件
-p 保留访问的修改时间,所有权和权限
hadoop fs -cp [-f] <目标文件> ... <本地位置>
-f 覆盖追加数据
hadoop fs -appendTOFile <本地文件> .. <目标文件>将所指定的本地文件内容追加到目标文件
dst如果文件不存在,将创建该文件
如果<lcalSrc>为-,则按标准输入读取
用作小文件合并
移动重命名
hadoop fs -mv <源文件> ... <修改后位置>角色
主角色:namenode
namenode是hadoop分布式文件系统的核心,架构中的主角色
namenode负责维护和管理文件系统元数据,包括名称空间目录结构,文件和块的位置信息、访问权限
因此,namenode成为了访问hdfs的唯一入口
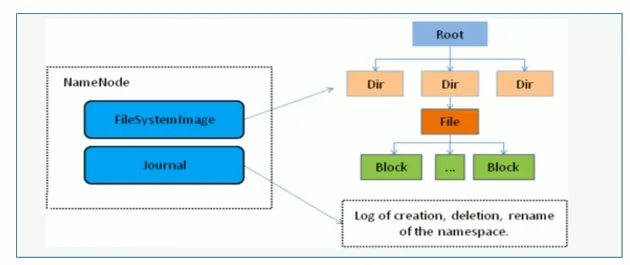
namenode内部通过内存和磁盘文件两种方式管理元数据
其中磁盘上的元数据文件包括Fsimages内存元数据镜像文件和edits log(journal)编辑日志
从角色:datanode
datanode是hadoop HDFS中的从角色,负责具体的数据块存储
datanode的数量决定了HDFS集群的整体数据存储能力。通过和namenode配合维护着数据块
主角色辅助角色:secondarynamenode
secondary namenode充当namenode的辅助接点,但不能代替namenode
主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”
namenode职责
namenode仅支持hdfs的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存粗实际数据
namenode知道hdfs中任何给定文件的块列表及其位置。使用此信息namenode知道如何从块中构建文件
namenode不持久存储每个文件中各个块存在的datanode的位置信息,这些信息会在系统启动时从datanode重建
namenode是hadoop集群中的单点故障
namenode所在及其通常会配置大量内存(随机存储器RAM)
datanode职责
datanode职责最终数据块block的存储。是集群的从角色,也成为slave
datanode启动时,会将自己注册到namenode并汇报自己负责持有的块列表
当某个datanode关闭时,不会影响数据的可用性。namenode将安排由其他datanode管理的块进行副本复刻
datanode所在机器通常配置有大量的磁盘空间,因此数据存放在datanode中
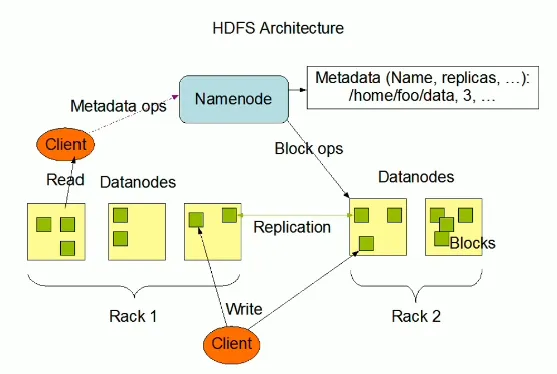
写入数据时数据流走向
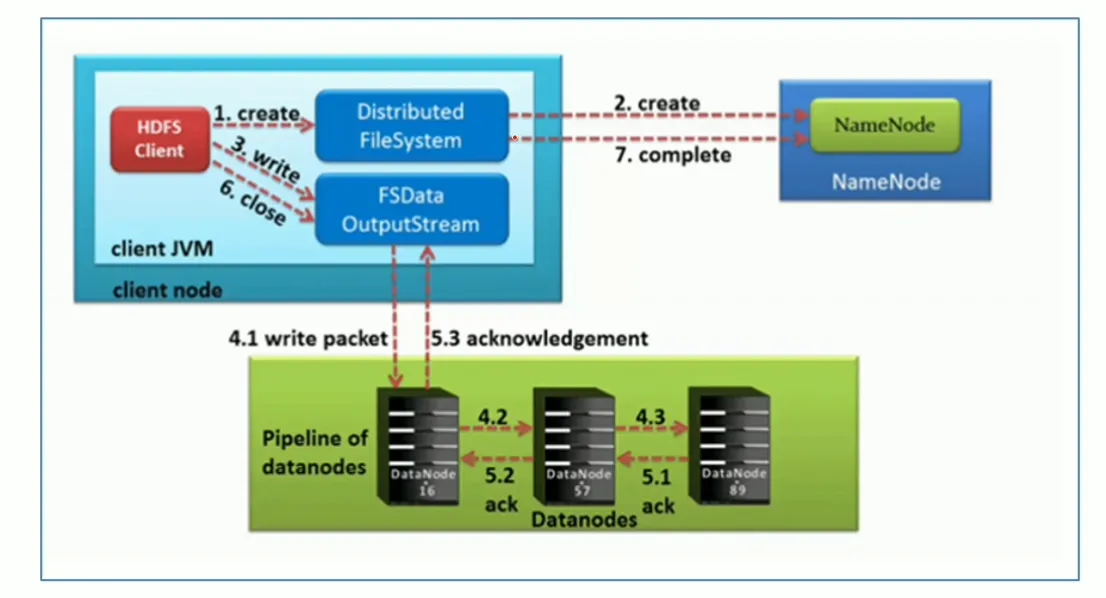
step1:hdfs客户端创建对象实例DistributedFileSystem,该对象中封装了与hdfs文件系统操作的相关方式。
step2:调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过后,NameNode就会为本次请求记下一条记录,返回fsdataoutputstream输出流对象给客户端用于写数据
setp3:客户端通过fsdataoutstream输出流开始写入数据
step4:客户端写入数据时,将数据分为一个个数据包(packet 默认64k),内部组件datastreamer请求NameNode挑选出适合存储数据的一组datanode地址,默认是3副本存储
step5:传输反方向上,会通过ack机制校验数据包传输是否成功
step6:客户端完成数据写入后,在fsdataoutstream输出流调用close()方法关闭
step7:DistributedFileSystem联系NameNode告知其文件写入成功,等待Name Node确认
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回。最小复制是由dfs.namenode.replication.min指定,默认是1。
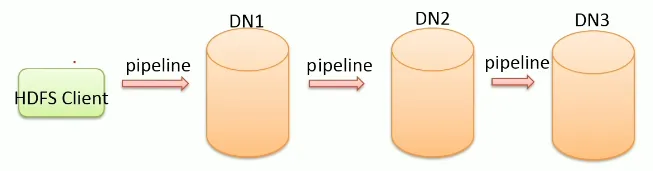
核心概念--Pipeline管道
Pipeline,中文翻译为管道。这是hdfs在上传文件写数据过程中采用的一种数据传输方式
在hdfs中数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每台机器的带宽,避免网络瓶颈和高延迟时的连接。最小化推送所有数据的延时
在线性推送模式下,每台机器所有的出口带宽都用于以最快的速度传输数据,而不是在多个接受者之间分配带宽
核心概念--ACK应答响应
ACK是确认符号,与tcp协议类似,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已收到确认无误。
在hdfs pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,以确保数据传输安全。
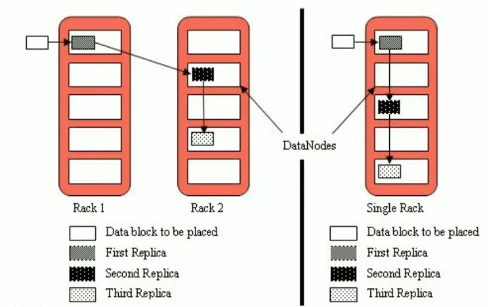
备份原则--默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定
第一副本:有限客户端本地,否则随机
第二副本:不同于第一块副本的不同机架
第三副本:与第二副本相同机架不同机器