大数据和数据分析是当今数字化时代两个密切相关但又有所区别的概念。以下是它们的详细对比和联系:
定义
大数据(Big Data)
大数据是指数据量巨大、类型多样、生成速度快的数据集合。它不仅包括传统的结构化数据(如数据库中的表格数据),还包括半结构化数据(如XML、JSON文件)和非结构化数据(如文本、图片、音频、视频等)。大数据的典型特征可以用“4V”来概括:
Volume(数据量大):数据规模巨大,通常达到TB(太字节)、PB(拍字节)甚至EB(艾字节)级别。
Variety(数据类型多样):数据来源广泛,格式复杂,包括文本、图像、音频、视频等多种形式。
Velocity(处理速度快):数据的生成和处理速度非常快,需要实时或近实时的处理能力。
Veracity(数据真实性):数据的质量和可靠性至关重要,但大数据中往往包含噪声和错误,需要进行清洗和验证。
数据分析(Data Analysis)
数据分析是指对数据进行收集、整理、处理和解释的过程,目的是提取有价值的信息,支持决策制定。数据分析可以应用于各种领域,包括商业、科学研究、医疗、金融等。它通常包括以下几个步骤:
数据收集:从不同的数据源获取数据。
数据清洗:去除噪声数据、填补缺失值、纠正错误等。
数据探索:通过统计分析、可视化等手段初步了解数据的特征和分布。
数据建模:根据分析目标选择合适的模型(如回归分析、聚类分析、分类分析等)。
结果解释:将分析结果转化为可操作的见解和建议。
关系
大数据是数据分析的基础
大数据为数据分析提供了丰富的数据资源。没有大数据的支持,数据分析的范围和深度会受到限制。大数据的多样性和海量性使得数据分析能够从更广泛的角度挖掘信息,发现隐藏的模式和趋势。数据分析是大数据的价值体现
大数据本身只是数据的集合,其价值需要通过数据分析来实现。数据分析通过对大数据的处理和挖掘,将数据转化为有价值的信息和知识,从而支持决策制定和业务优化。
而Hadoop可以完美胜任用以解决以上问题,Hadoop的分布式文件系统(HDFS)可以高效的存储TB甚至PB以上的数据。
hadoop核心组件
Hadoop在大数据领域有着极为重要的地位,他是一个开源的分布式计算框架,为处理海量数据提供了强大的支持,核心组件包括HDFS、MapReduce、YARN。
HDFS(Hadoop Distributed File System)
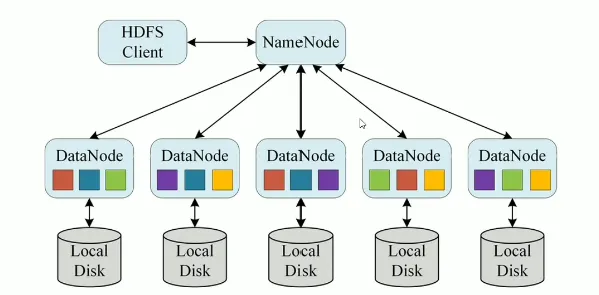
hdfs主要是用于处理大数据存储问题的,分布式意味着hdfs是横跨在多台计算机上的存储系统
hdfs是一种能够在普通硬件上运行的分布式文件系统,他是高容错的,适应于具有大数据收集的应用,非常适合存储TB以及PB级别的大型数据
hdfs使用多台计算机存储文件,并且提供统一的访问入口,操作体验像是访问普通文件系统一样使用分布式文件系统
MapReduce
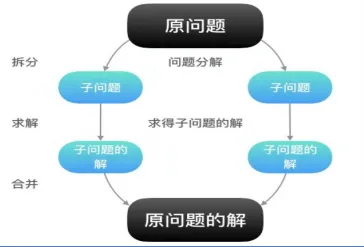
MapReduce是一个分布式的并行处理框架
mapreduce的思想核心是“先分再和,分而治之”
所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。
这种思想来源于日常生活与工作时的经验。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
Map表示第一阶段,负责“拆分”:即把复杂的任务分解为若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce表示第二阶段,负责“合并”:即对map阶段的结果进行全汇总。
这两个阶段合起来正是MapReduce思想的体现。
YARN(Yet Another Resource Negotiaor)
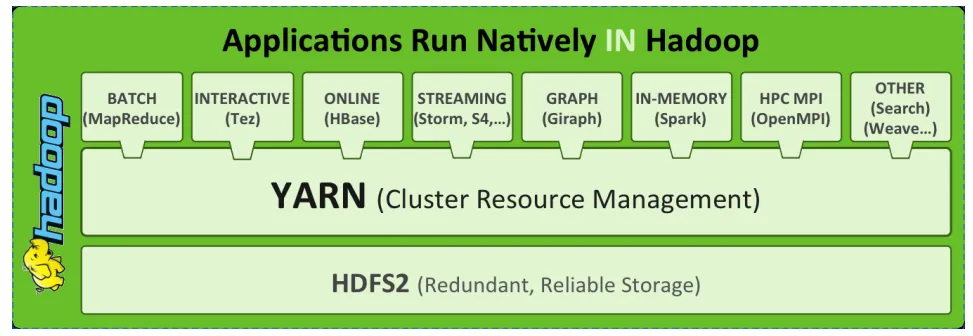
Apache Hadoop YARN (Yet Another Resource Negotiator ,另一种资源协调者)是一种新的Hadoop资源管理器。
YARN是一种通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
他的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Hadoop现状
HDFS作为分布式文件存储系统,处在生态圈的底层与核心地位;
YARN作为分布式通用的集群资源管理系统和任务调度平台,支撑各种计算引擎运行,保证了Hadoop地位
MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计的模型所产生的弊端导致企业一线几乎不再直接使用Mapreduce进行编程处理,但是很多软件的底层依然再使用MapReduce引擎来处理数据。